This page provides research highlights. Please see our publications page for more information and/or feel free to contact us. We enjoy discussing interesting ideas and pursuing new collaborations.
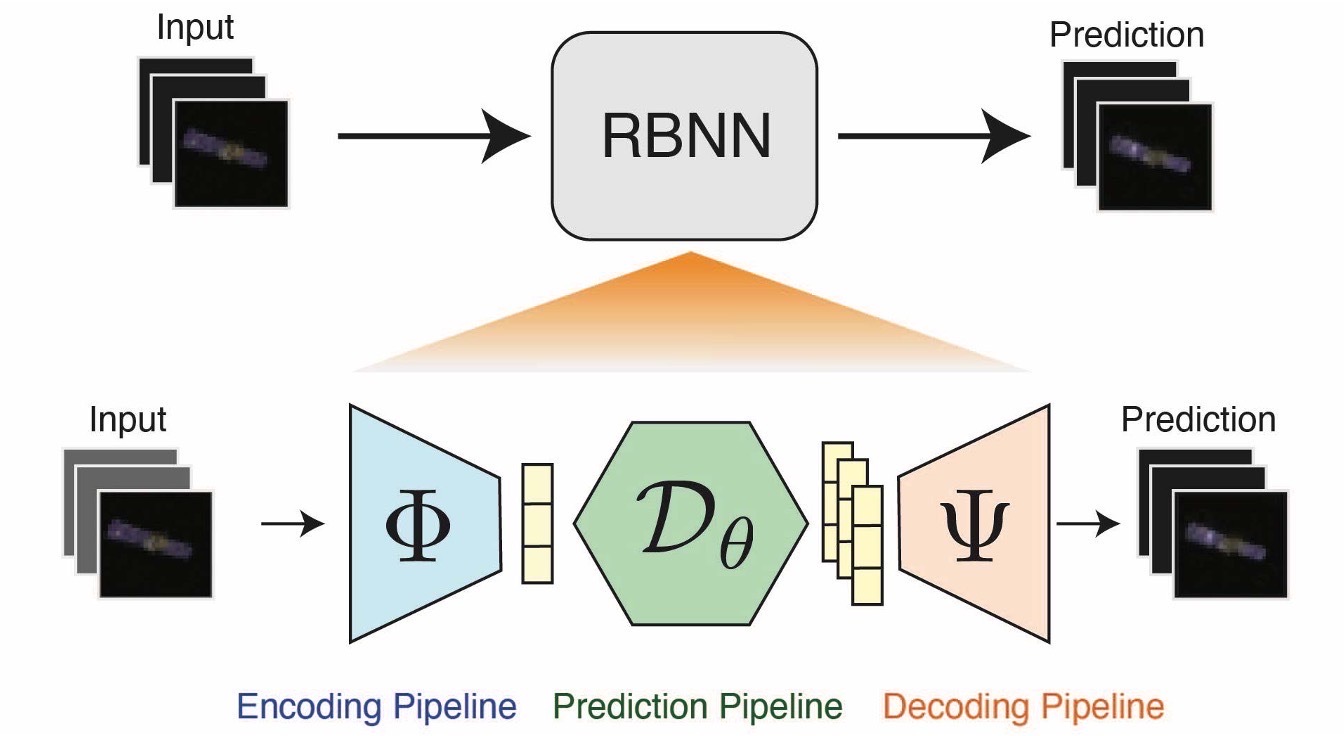
Learning to Predict 3D Rotational Dynamics from Images of a Rigid Body with Unknown Mass Distribution
Researchers: Justice Joseph Mason, Christine Allen-Blanchette, Nicholas Zolman, Elizabeth Davison, and Naomi Ehrich Leonard
Abstract: In many real-world settings, image observations of freely rotating 3D rigid bodies may be available when low-dimensional measurements are not. However, the high-dimensionality of image data precludes the use of classical estimation techniques to learn the dynamics. The usefulness of standard deep learning methods is also limited, because an image of a rigid body reveals nothing about the distribution of mass inside the body, which, together with initial angular velocity, is what determines how the body will rotate. We present a physics-based neural network model to estimate and predict 3D rotational dynamics from image sequences. We achieve this using a multi-stage prediction pipeline that maps individual images to a latent representation homeomorphic to 𝐒𝐎(3), computes angular velocities from latent pairs, and predicts future latent states using the Hamiltonian equations of motion. We demonstrate the efficacy of our approach on new rotating rigid-body datasets of sequences of synthetic images of rotating objects, including cubes, prisms and satellites, with unknown uniform and non-uniform mass distributions. Our model outperforms competing baselines on our datasets, producing better qualitative predictions and reducing the error observed for the state-of-the-art Hamiltonian Generative Network by a factor of 2.
Related Publications:
J. Mason, C. Allen-Blanchette, N. Zolman, E. Davison, and N. E. Leonard, “Learning to Predict 3D Rotational Dynamics from Images of a Rigid Body with Unknown Mass Distribution”, in Aerospace, 2023. [PDF]

Nonlinear Opinion Dynamics with Tunable Sensitivity
Researchers: Anastasia Bizyaeva, Alessio Franci, and Naomi Ehrich Leonard
Abstract: We propose a continuous-time multi-option nonlinear generalization of classical linear weighted-average opinion dynamics. Nonlinearity is introduced by saturating opinion exchanges, and this is enough to enable a significantly greater range of opinion-forming behaviors with our model as compared to existing linear and nonlinear models. For a group of agents that communicate opinions over a network, these behaviors include multistable agreement and disagreement, tunable sensitivity to input, robustness to disturbance, flexible transition between patterns of opinions, and opinion cascades. We derive network-dependent tuning rules to robustly control the system behavior and we design state-feedback dynamics for the model parameters to make the behavior adaptive to changing external conditions.} The model provides new means for systematic study of dynamics on natural and engineered networks, from information spread and political polarization to collective decision making and dynamic task allocation.
Related Publications:
A. Bizyaeva, A. Franci, and N. E. Leonard, “Nonlinear Opinion Dynamics with Tunable Sensitivity”, in IEEE Transactions on Automatic Control, 2022. [arXiv][IEEEXplore]
A. Bizyaeva, G. Amorim, M. Santos, A. Franci, and N. E. Leonard, “Switching Transformations for Decentralized Control of Opinion Patterns in Signed Networks: Application to Dynamic Task Allocation”, in Control Systems Letters, vol. 6, pp. 3463-3468, 2022. [IEEEXplore]
A. Bizyaeva, A. Matthews, A. Franci, and N. E. Leonard, “Patterns of nonlinear opinion formation on networks”, in 2021 American Control Conference (ACC), pp. 2739-2744, 2021. [arXiv][IEEEXplore]
A. Franci, M. Golubitsky, A. Bizyaeva, and N. E. Leonard, “A model-independent theory of consensus and dissensus decision making”, in arXiv:1909.05765v2 [math.OC]. [arXiv]
R. Gray, A. Franci, V. Srivastava, and N. E. Leonard, “Multi-agent decision-making dynamics inspired by honeybees”, in IEEE Transactions on Control of Network Systems, Vol. 5, No. 2, June 2018, pp. 793-806. [PDF] [arXiv]
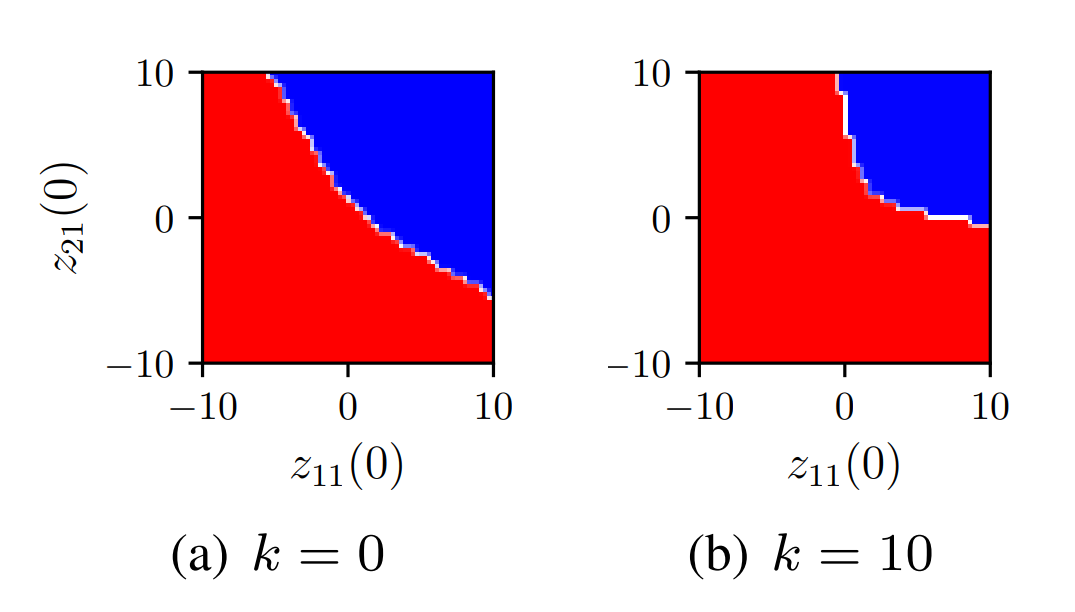
Tuning Cooperative Behavior in Games with Nonlinear Opinion Dynamics
Researchers: Shinkyu Park, Anastasia Bizyaeva, Mari Kawakatsu, Alessio Franci, and Naomi Ehrich Leonard
Abstract: We examine the tuning of cooperative behavior in repeated multi-agent games using an analytically tractable, continuous-time, nonlinear model of opinion dynamics. Each modeled agent updates its real-valued opinion about each available strategy in response to payoffs and other agent opinions, as observed over a network. We show how the model provides a principled and systematic means to investigate behavior of agents that select strategies using rationality and reciprocity, key features of human decision-making in social dilemmas. For two-strategy games, we use bifurcation analysis to prove conditions for the bistability of two equilibria and conditions for the first (second) equilibrium to reflect all agents favoring the first (second) strategy. We prove how model parameters, e.g., level of attention to opinions of others (reciprocity), network structure, and payoffs, influence dynamics and, notably, the size of the region of attraction to each stable equilibrium. We provide insights by examining the tuning of the bistability of mutual cooperation and mutual defection and their regions of attraction for the repeated prisoner’s dilemma and the repeated multi-agent public goods game. Our results generalize to games with more strategies, heterogeneity, and additional feedback dynamics, such as those designed to elicit cooperation.
Related Publications:
S. Park, A. Bizyaeva, M. Kawakatsu, A. Franci, and N. E. Leonard, “Tuning Cooperative Behavior in Games with Nonlinear Opinion Dynamics”, in IEEE Control Systems Letters, vol. 6, pp. 2030-2035, 2022. [PDF]
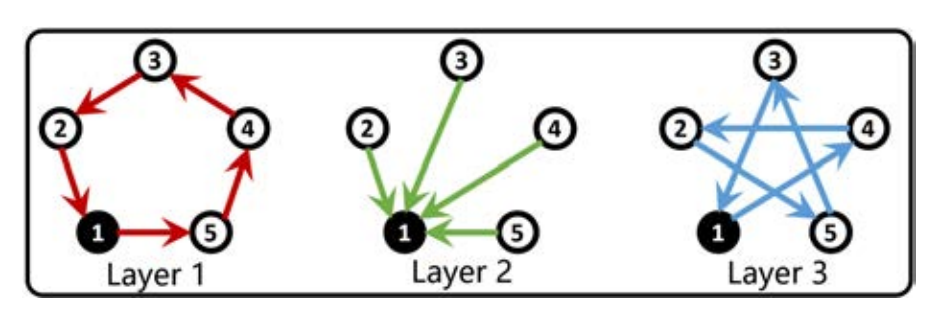
Influence Spread in the Heterogeneous Multiplex Linear Threshold Model
Researchers: Yaofeng Desmond Zhong, Vaibhav Srivastava, and Naomi Ehrich Leonard
Abstract: The linear threshold model (LTM) has been used to study spread on single-layer networks defined by one inter-agent sensing modality and agents homogeneous in protocol. We define and analyze the heterogeneous multiplex LTM to study spread on multi-layer networks with each layer representing a different sensing modality and agents heterogeneous in protocol. Protocols are designed to distinguish signals from different layers: an agent becomes active if a sufficient number of its neighbors in each of any a of the m layers is active. We focus on Protocol OR, when a=1, and Protocol AND, when a=m, which model agents that are most and least readily activated, respectively. We develop theory and algorithms to compute the size of the spread at steady state for any set of initially active agents and to analyze the role of distinguished sensing modalities, network structure, and heterogeneity. We show how heterogeneity manages the tension in spreading dynamics between sensitivity to inputs and robustness to disturbances.
Related Publications:
Y. D. Zhong, V. Srivastava and N. E. Leonard, “Influence Spread in the Heterogeneous Multiplex Linear Threshold Model,” in IEEE Transactions on Control of Network Systems (Early Access). [PDF]
Y. D. Zhong, V. Srivastava and N. E. Leonard, “On the linear threshold model for diffusion of innovations in multiplex social networks,” IEEE Conference on Decision and Control (CDC), 2017, pp. 2593-2598. [PDF]
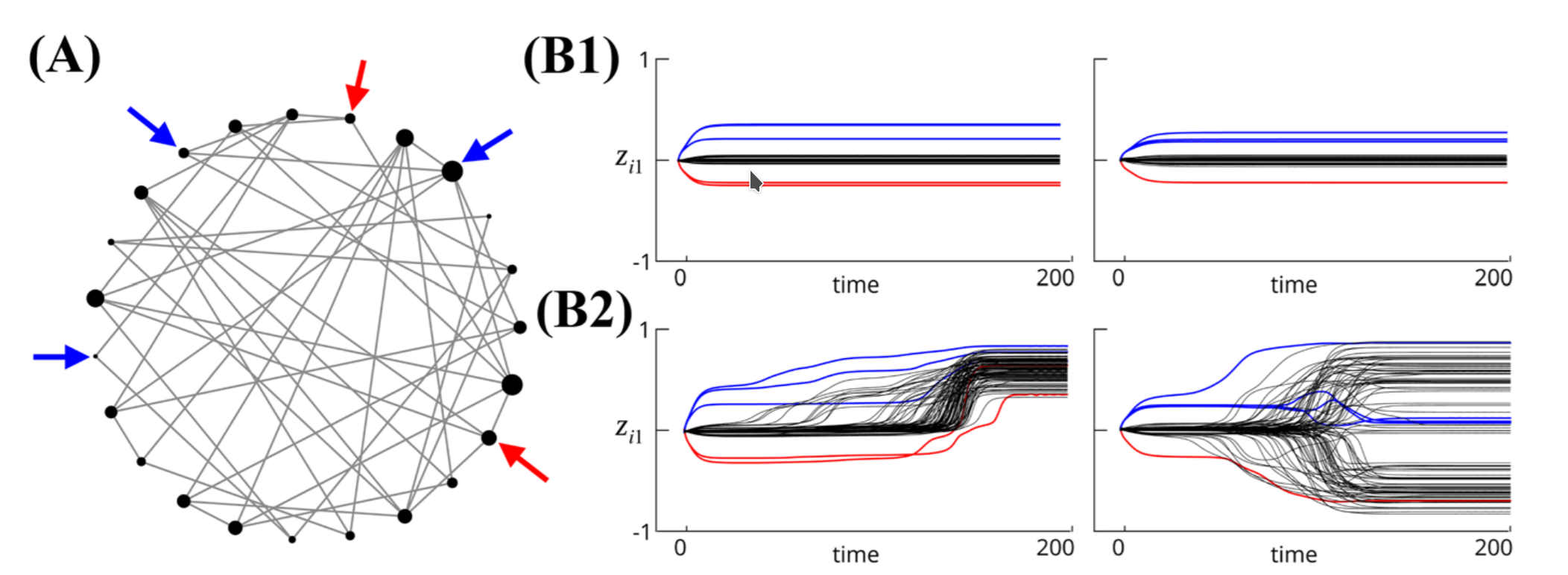
Analysis and Control of Agreement and Disagreement Opinion Cascades
Researchers: Alessio Franci, Anastasia Bizyaeva, Shinkyu Park, and Naomi Ehrich Leonard
Abstract: We introduce and analyze a continuous time and state-space model of opinion cascades on networks of large numbers of agents that form opinions about two or more options. By leveraging our recent results on the emergence of agreement and disagreement states, we introduce novel tools to analyze and control agreement and disagreement opinion cascades. New notions of agreement and disagreement centrality, which depend only on network structure, are shown to be key to characterizing the nonlinear behavior of agreement and disagreement opinion formation and cascades. Our results are relevant for the analysis and control of opinion cascades in real-world networks, including biological, social, and artificial networks, and for the design of opinion-forming behaviors in robotic swarms. We illustrate an application of our model to a multi-robot task-allocation problem and discuss extensions and future directions opened by our modeling framework.
Related Publications:
A. Franci, A. Bizyaeva, S. Park, and N. E. Leonard, “Analysis and control of agreement and disagreement opinion cascades”, Swarm Intelligence, Vol. 15, No. 1, 2021. [PDF]
A. Bizyaeva, T. Sorochkin, A. Franci, and N. E. Leonard, “Control of Agreement and Disagreement Cascades with Distributed Inputs”, IEEE Conference on Decision and Control (CDC), Austin, TX, USA, 2021. [arXiv]
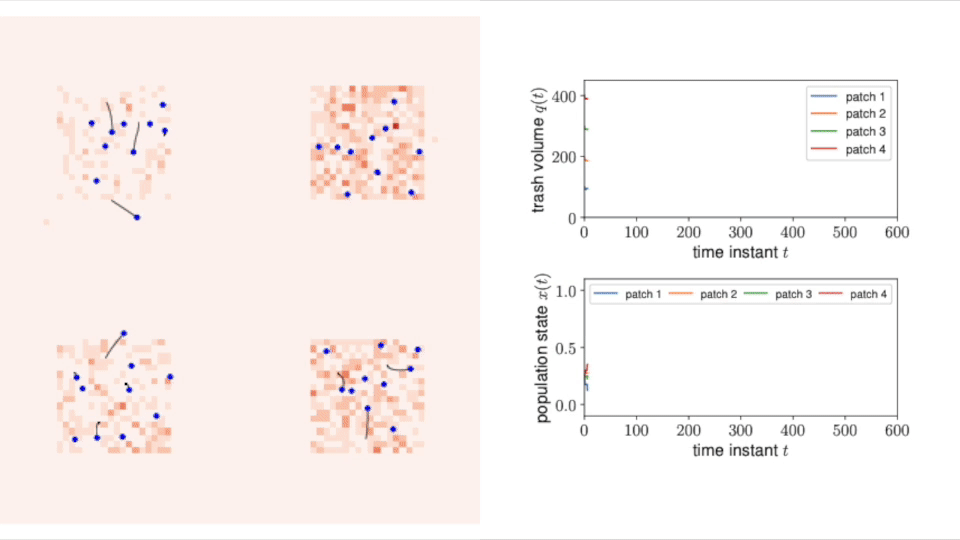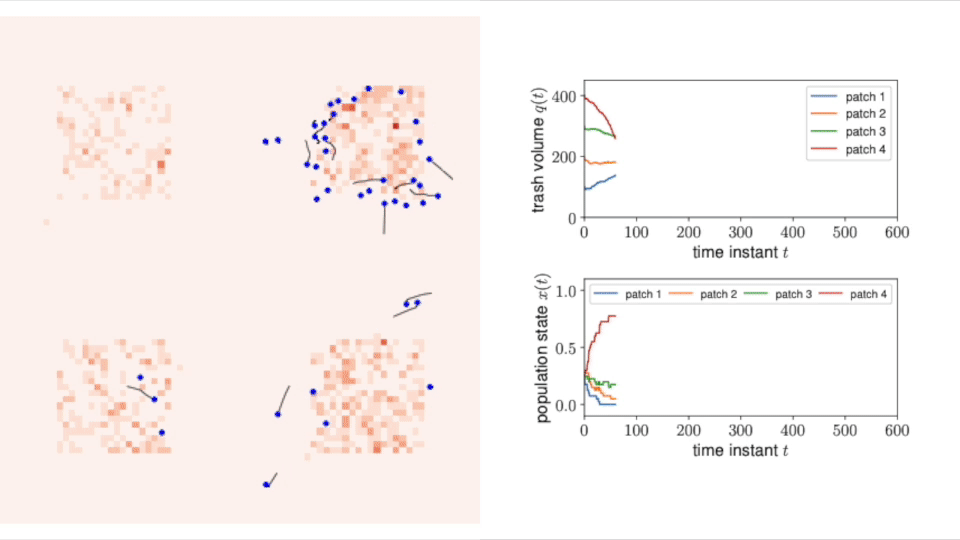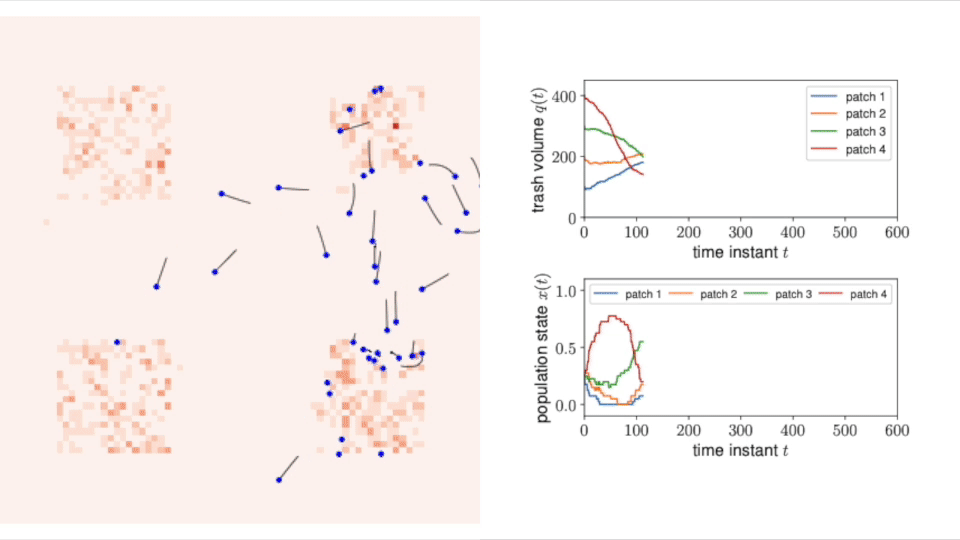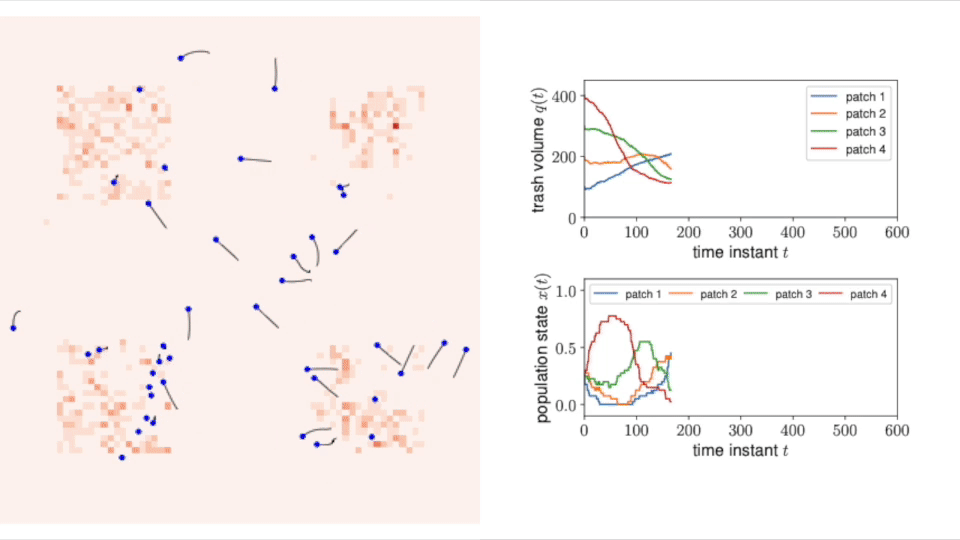
Multi-Robot Task Allocation Games in Dynamically Changing Environments
Researchers: Shinkyu Park, Desmond Zhong, and Naomi Ehrich Leonard
Abstract: We propose a game-theoretic multi-robot task allocation framework that enables a large team of robots to optimally allocate tasks in dynamically changing environments. As our main contribution, we design a decision-making algorithm that defines how the robots select tasks to perform and how they repeatedly revise their task selections in response to changes in the environment. Our convergence analysis establishes that the algorithm enables the robots to learn and asymptotically achieve the optimal stationary task allocation. Through experiments with a multi-robot trash collection application, we assess the algorithm’s responsiveness to changing environments and resilience to failure of individual robots.
Related Publications:
S. Park, Y. D. Zhong, and N. E. Leonard, “Multi-robot task allocation games in dynamically changing environments”, in International Conference on Robotics and Automation (ICRA), Xi’an, China, 2021. [PDF]
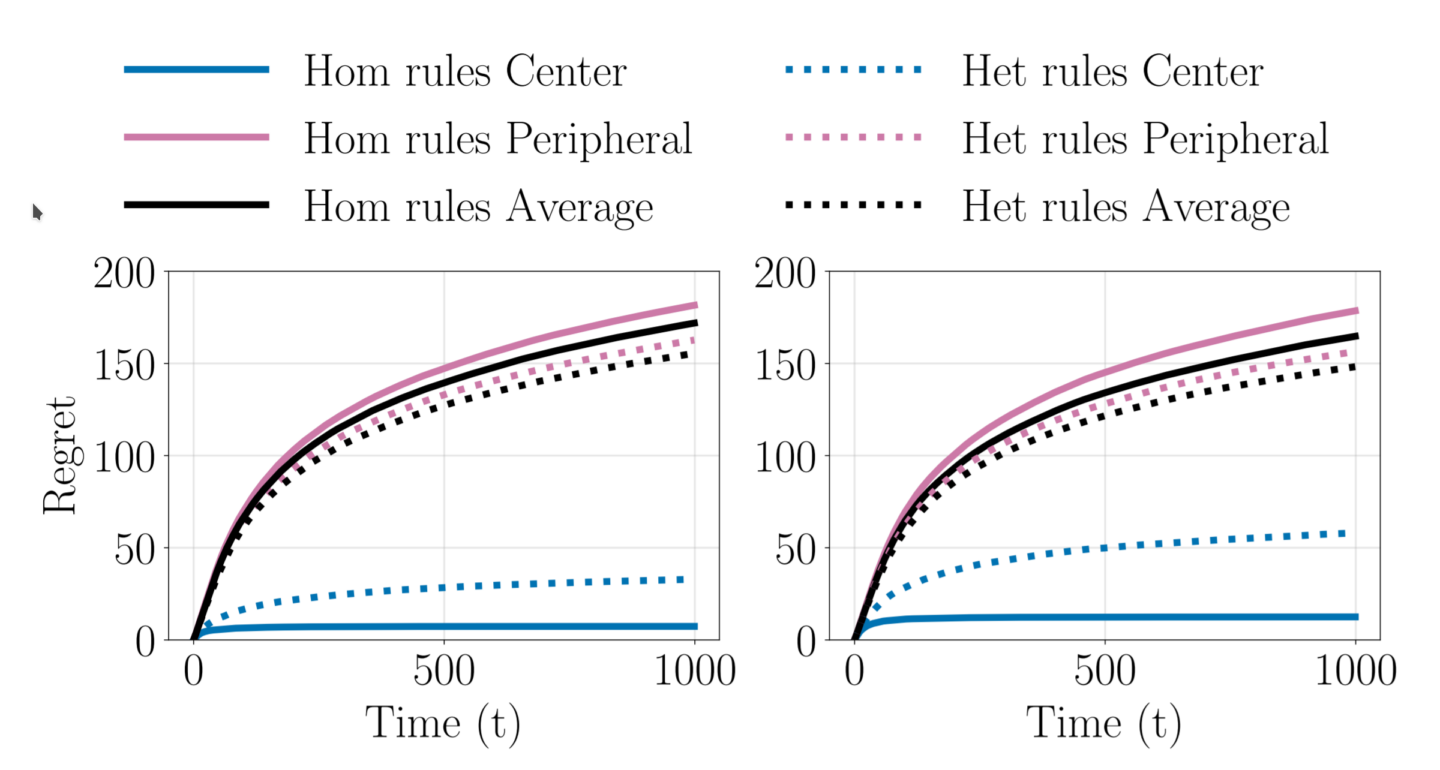
Heterogeneous Explore-Exploit Strategies on Multi-Star Networks
Researchers: Udari Madhushani and Naomi Ehrich Leonard
Abstract: We investigate the benefits of heterogeneity in multi-agent explore-exploit decision making where the goal of the agents is to maximize cumulative group reward. To do so we study a class of distributed stochastic bandit problems in which agents communicate over a multi-star network and make sequential choices among options in the same uncertain environment. Typically, in multi-agent bandit problems, agents use homogeneous decision-making strategies. However, group performance can be improved by incorporating heterogeneity into the choices agents make, especially when the network graph is irregular, i.e., when agents have different numbers of neighbors. We design and analyze new heterogeneous explore-exploit strategies, using the multi-star as the model irregular network graph. The key idea is to enable center agents to do more exploring than they would do using the homogeneous strategy, as a means of providing more useful data to the peripheral agents. In the case all agents broadcast their reward values and choices to their neighbors with the same probability, we provide theoretical guarantees that group performance improves under the proposed heterogeneous strategies as compared to under homogeneous strategies. We use numerical simulations to illustrate our results and to validate our theoretical bounds.
Related Publications:
U. Madhushani and N. E. Leonard, “Heterogeneous Explore-Exploit Strategies on Multi-Star Networks,” in IEEE Control Systems Letters, vol. 5, no. 5, pp. 1603-1608, Nov. 2021. [arXiv][PDF]
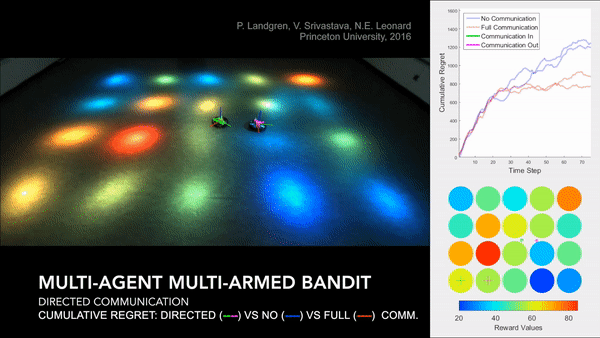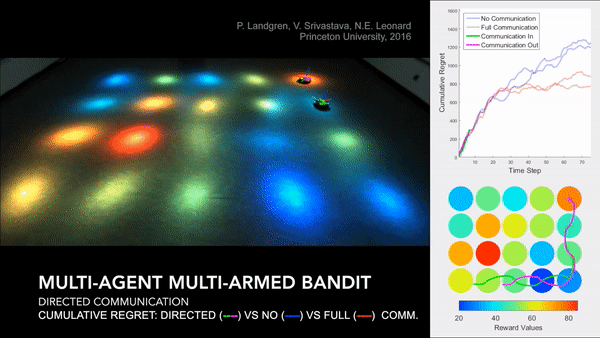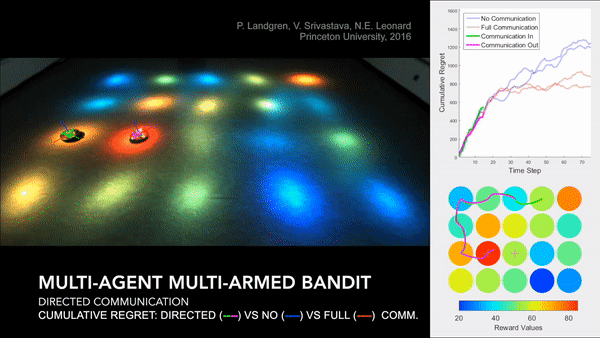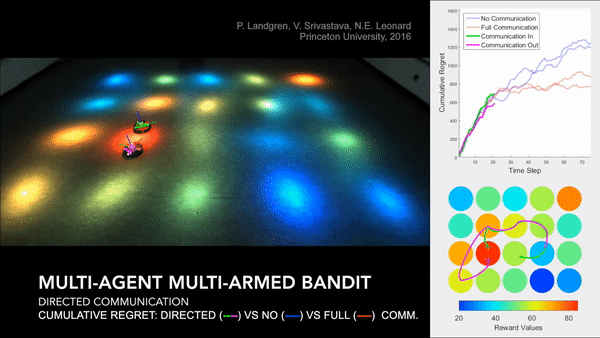
Distributed Cooperative Decision Making in Multi-agent Multi-armed Bandits
Researchers: Peter Landgren, Vaibhav Srivastava, and Naomi Ehrich Leonard
Abstract: We study a distributed decision-making problem in which multiple agents face the same multi-armed bandit (MAB), and each agent makes sequential choices among arms to maximize its own individual reward. The agents cooperate by sharing their estimates over a fixed communication graph. We consider an unconstrained reward model in which two or more agents can choose the same arm and collect independent rewards. And we consider a constrained reward model in which agents that choose the same arm at the same time receive no reward. We design a dynamic, consensus-based, distributed estimation algorithm for cooperative estimation of mean rewards at each arm. We leverage the estimates from this algorithm to develop two distributed algorithms: coop-UCB2 and coop-UCB2-selective-learning, for the unconstrained and constrained reward models, respectively. We show that both algorithms achieve group performance close to the performance of a centralized fusion center. Further, we investigate the influence of the communication graph structure on performance. We propose a novel graph explore-exploit index that predicts the relative performance of groups in terms of the communication graph, and we propose a novel nodal explore-exploit centrality index that predicts the relative performance of agents in terms of the agent locations in the communication graph.
Related Publications:
P. Landgren, V. Srivastava, and N. E. Leonard, “Distributed cooperative decision making in multi-agent multi-armed bandits”, in Automatica, Vol. 125, 2021. Mar. 2021. [arXiv][PDF]
P. Landgren, V. Srivastava, and N. E. Leonard, “Distributed cooperative decision-making in multiarmed bandits: Frequentist and Bayesian algorithms”, in IEEE Conference on Decision and Control (CDC), Las Vegas, NV, 2016, pp. 167-172. [PDF] [PDF with correction] [arXiv]
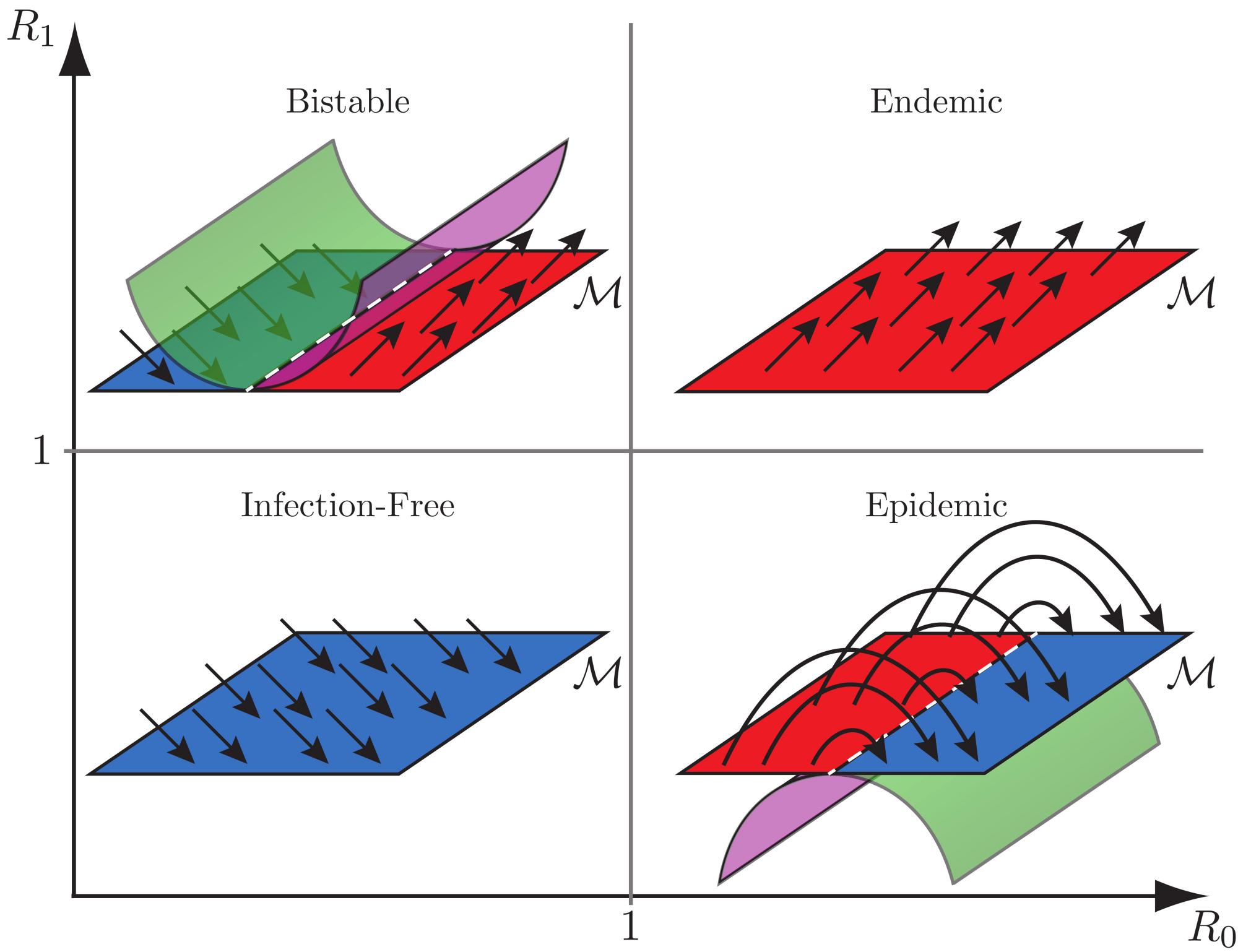
Adaptive susceptibility and heterogeneity in contagion models on networks
Researchers: Renato Pagliara and Naomi Ehrich Leonard
Abstract: Contagious processes, such as spread of infectious diseases, social behaviors, or computer viruses, affect biological, social, and technological systems. Epidemic models for large populations and finite populations on networks have been used to understand and control both transient and steady-state behaviors. Typically it is assumed that after recovery from an infection, every agent will either return to its original susceptible state or acquire full immunity to reinfection. We study the network SIRI (Susceptible-Infected-Recovered-Infected) model, an epidemic model for the spread of contagious processes on a network of heterogeneous agents that can adapt their susceptibility to reinfection. The model generalizes existing models to accommodate realistic conditions in which agents acquire partial or compromised immunity after first exposure to an infection. We prove necessary and sufficient conditions on model parameters and network structure that distinguish four dynamic regimes: infection-free, epidemic, endemic, and bistable. For the bistable regime, which is not accounted for in traditional models, we show how there can be a rapid resurgent epidemic after what looks like convergence to an infection-free population. We use the model and its predictive capability to show how control strategies can be designed to mitigate problematic contagious behaviors.
Related Publications:
R. Pagliara, and N. E. Leonard, “Adaptive susceptibility and heterogeneity in contagion models on networks”, in IEEE Transactions on Automatic Control, vol. 66, no. 2, pp. 581-594, Feb. 2021. [arXiv][PDF]
R. Pagliara, B. Dey and N. E. Leonard, “Bistability and resurgent epidemics in reinfection models”, in IEEE Control Systems Letters, Vol. 2, No. 2, pp. 290-295, 2018. [PDF]
Y. Zhou, S. A. Levin, and N. E. Leonard, “Active control and sustained oscillations in actSIS epidemic dynamics”, in IFAC Workshop on Cyber-Physical & Human Systems (CPHS), 2020. [arXiv]
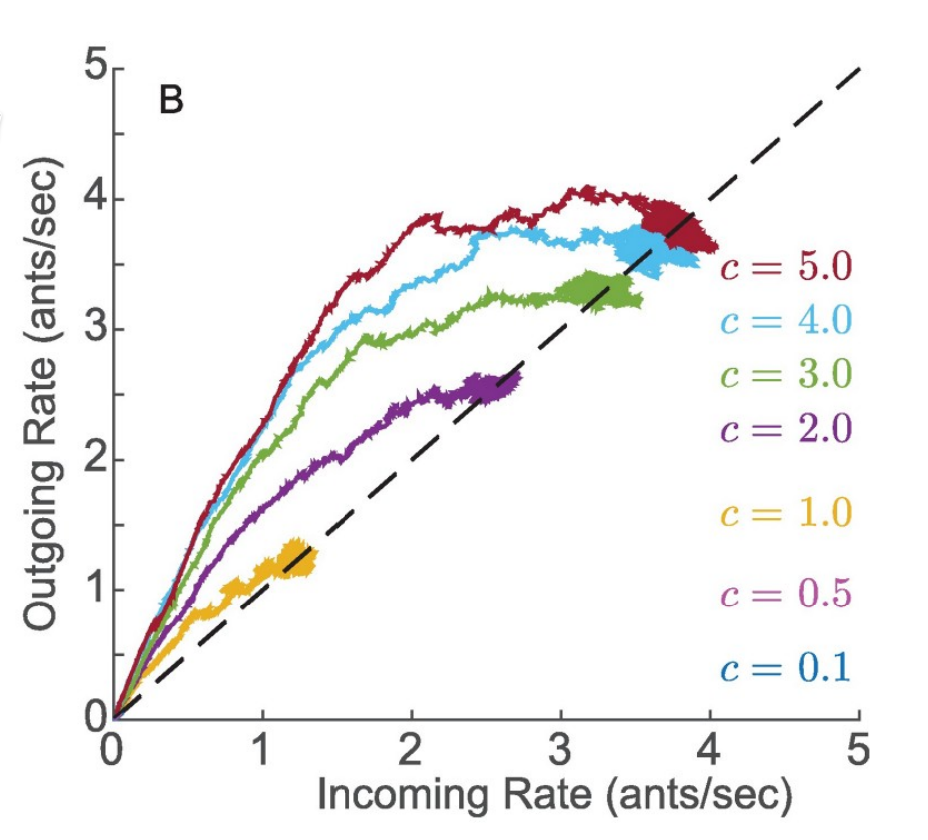
Regulation of harvester ant foraging as a closed-loop excitable system
Researchers: Renato Pagliara, Deborah M. Gordon, and Naomi Ehrich Leonard
Abstract: Ant colonies regulate activity in response to changing conditions without using centralized control. Desert harvester ant colonies forage for seeds, and regulate foraging to manage a tradeoff between spending and obtaining water. Foragers lose water while outside in the dry air, but ants obtain water by metabolizing the fats in the seeds they eat. Previous work shows that the rate at which an outgoing forager leaves the nest depends on its recent rate of brief antennal contacts with incoming foragers carrying food. We examine how this process can yield foraging rates that are robust to uncertainty and responsive to temperature and humidity across minute-to-hour timescales. To explore possible mechanisms, we develop a low-dimensional analytical model with a small number of parameters that captures observed foraging behavior. The model uses excitability dynamics to represent response to interactions inside the nest and a random delay distribution to represent foraging time outside the nest. We show how feedback from outgoing foragers returning to the nest stabilizes the incoming and outgoing foraging rates to a common value determined by the volatility of available foragers. The model exhibits a critical volatility above which there is sustained foraging at a constant rate and below which foraging stops. To explain how foraging rates adjust to temperature and humidity, we propose that foragers modify their volatility after they leave the nest and become exposed to the environment. Our study highlights the importance of feedback in the regulation of foraging activity and shows how modulation of volatility can explain how foraging activity responds to conditions and varies across colonies. Our model elucidates the role of feedback across many timescales in collective behavior, and may be generalized to other systems driven by excitable dynamics, such as neuronal networks.
Related Publications:
R. Pagliara, D. M. Gordon, and N. E. Leonard, “Regulation of harvester ant foraging as a closed-loop excitable system”, in PLoS Computational Biology, Vol. 14, No. 12, pp. 1-25, Dec. 2018. [PDF]

Optimal evasive strategies for multiple interacting agents with motion constraints
Researchers: William Lewis Scott and Naomi Ehrich Leonard
Abstract: We derive and analyze optimal control strategies for a system of pursuit and evasion with a single speed-limited pursuer, and multiple heterogeneous evaders with limits on speed, angular turning rate, and lateral acceleration. The goal of the pursuer is to capture a single evader in the minimum time possible, and the goal of each evader is to avoid capture if possible, or else delay capture for as long as possible. Optimal strategies are derived for the one-on-one differential game, and these form the basis of strategies for the multiple-evader system. We propose a pursuer strategy of optimal target selection which leads to capture in bounded time. For evaders, we prove how any evader not initially targeted can avoid capture. We also consider optimal strategies for agents with radius-limited sensing capabilities, proving conditions for evader capture avoidance through a local strategy of risk reduction. We show how evaders aggregate in response to a pursuer, much like animals behave in the wild.
Related Publications:
W. L. Scott and N. E. Leonard, “Minimum-time trajectories for steered agent with constraints on speed, lateral acceleration, and turning rate”, in ASME Journal of Dynamic Systems, Measurement and Control, Vol. 140, No. 7, p. 071017, July 2018. [PDF]
W. L. Scott and N. E. Leonard, “Dynamics of pursuit and evasion in a heterogeneous herd”, in IEEE Conference on Decision and Control (CDC), pp. 2920-2925, 2014. [PDF]
W. L. Scott and N. E. Leonard, “Pursuit, herding and evasion: A three-agent model of caribou predation”, in American Control Conference (ACC), pp. 2978-2983, 2013. [PDF]